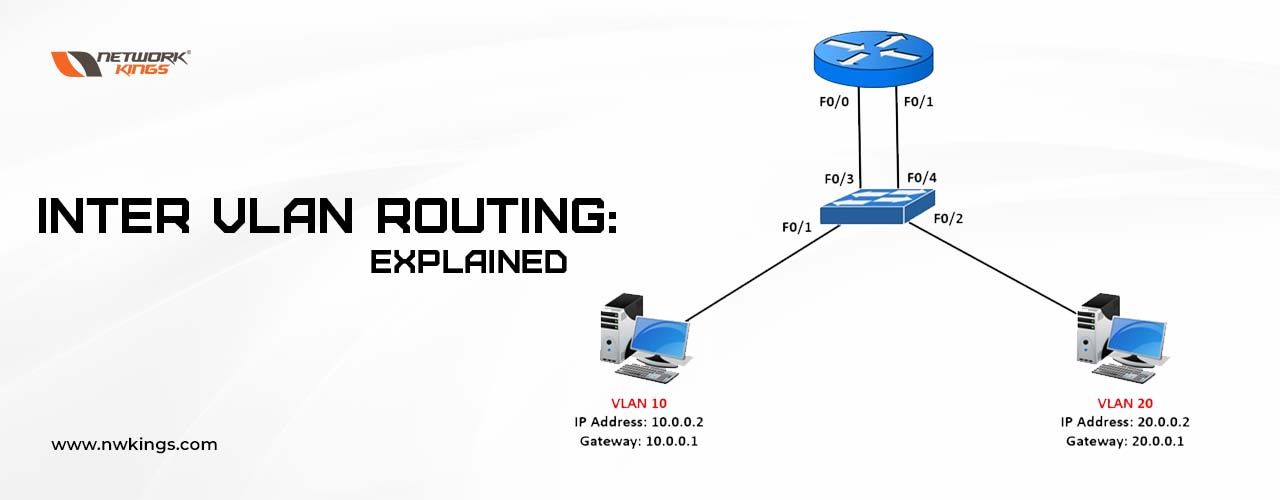
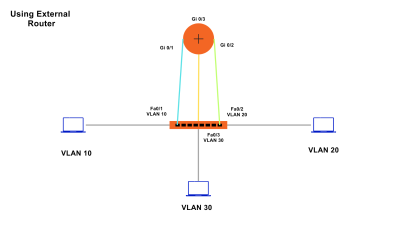
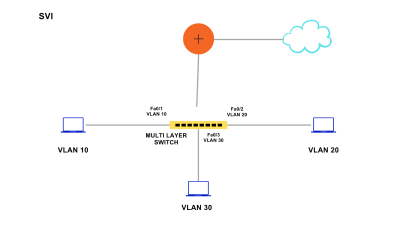
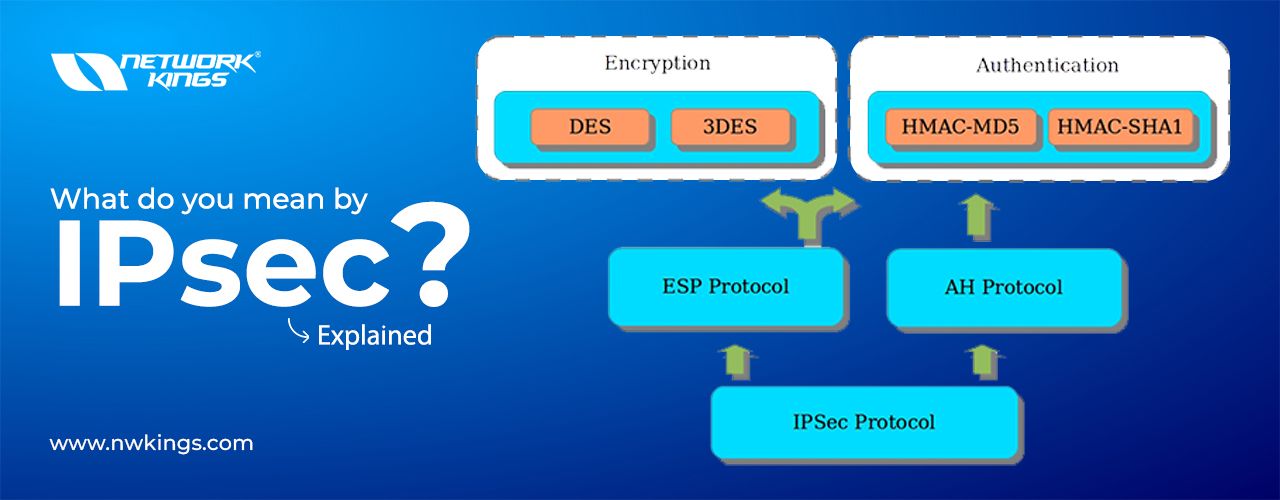
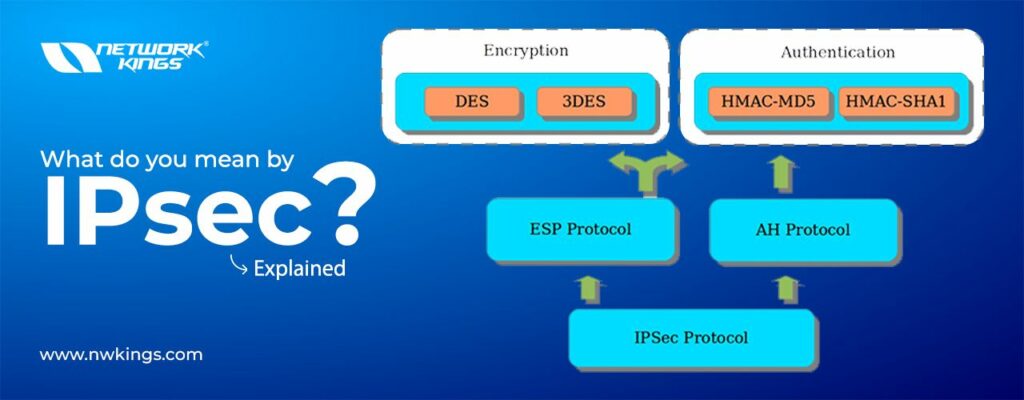
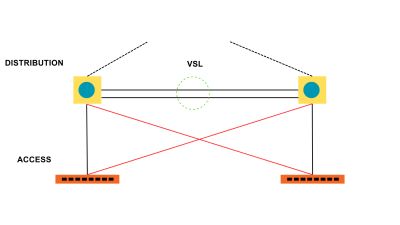
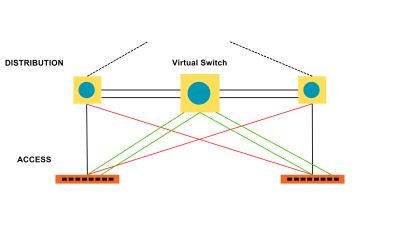
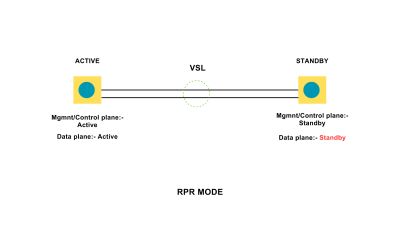
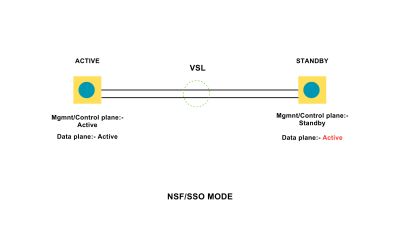
VLANs divide traffic in a LAN according to the needs and increase the broadcast domain. There are methods using which two different Vans can communicate with each other. This process is known as Inter-VLAN routing.
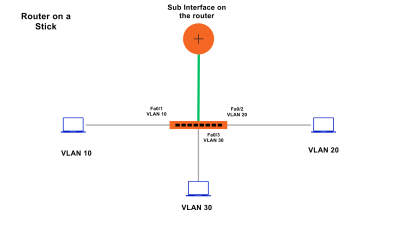
We have discussed Inter-VLAN routing and different methods that can be used to make different VLANs communicate with each other. Let us now see the configuration of one of the popular methods of Inter-VLAN routing, i.e., Router on a stick.
What is Router on a Stick?
Router on a stick or ROAS is a method in which we learn to create a sub-interface on the router and use VLAN tagging to differentiate between the traffic. Let us see how this can be attained.
Router on a Stick Configuration:-
Let us take a simple topology with VLAN 10 and VLAN 20.
VLAN 10 is used for sales and VLAN 20 is used for accounts.
PC 1 and 2 are connected to the port in VLAN 10 and are configured with IP 10.10.10.10 and 10.10.10.11
PC 3 and PC 4 are connected to the port in VLAN 20 and are configured with IP 10.10.20.10 and 10.10.20.11
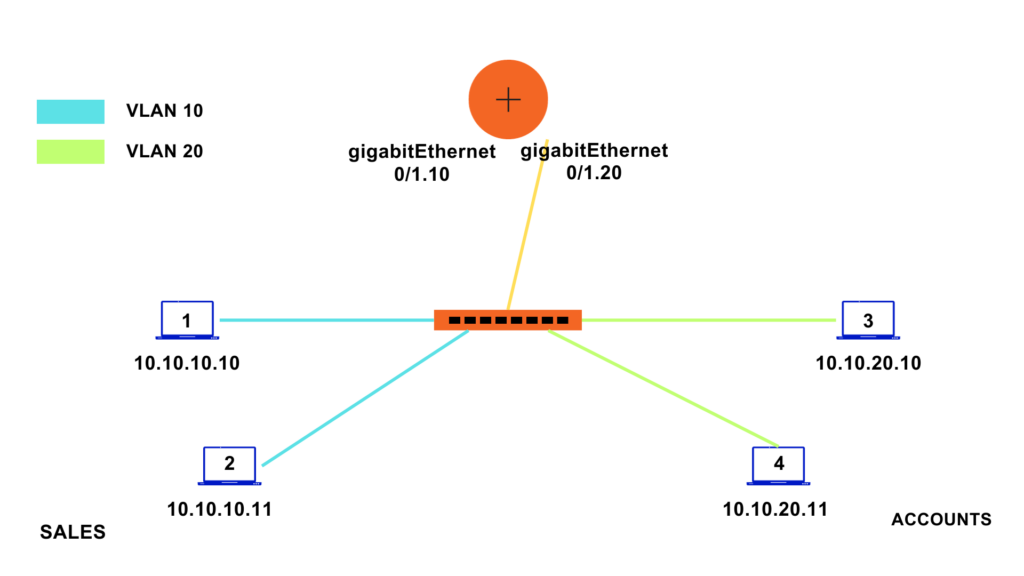
Configuration on Switch:-
Interface FastEthernet 0/2 and fastEthernet 0/3 are in VLAN 10 while interface FastEthernet 0/4 and FastEthernet 0/5 are assigned to VLAN 20.
Interface FastEthernet 0/1 of the switch should be configured as a trunk because all the VLAN passes to the router from this link only.
S1#configure terminal
S1(config)#vlan 10
S1(config-vlan)#name sales
S1(config-vlan)#exit
S1(config)#vlan 20
S1(config-vlan)#name accounts
S1(config-vlan)#exit
S1(config)#interface range fastEthernet 0/2 – 3
S1(config-if-range)#switchport mode access
S1(config-if-range)#switchport access vlan 10
S1(config-if-range)#exit
S1(config)#interface range fastEthernet 0/4 – 5
S1(config-if-range)#switchport mode access
S1(config-if-range)#switchport access vlan 20
S1(config-if-range)#exit
S1(config)#interface fastEthernet 0/1
S1(config-if)#switchport mode trunk
Configuration on Router:-
R1(config)#interface GigabitEthernet0/1
R1(config-if)#no ip address
(We will configure different IP addresses on different sub-interfaces)
R1(config-if)#no shutdown
R1(config-if)#exit
R1(config)#interface gigabitEthernet 0/1.10
%LINK-5-CHANGED: Interface GigabitEthernet0/1.10, changed state to up
Sub interface comes up, no need to give a shutdown command here since the actual physical interface i.e. GigabitEthernet0/1 is already up.
R1(config-subif)#encapsulation dot1Q 10
Tagging VLAN 10 to router sub-interface so that routers know which subinterface the traffic belongs to whenever traffic with VLAN 10 comes. Also, whenever traffic leaves the 1.10 subinterface a VLAN 10 will be assigned to it.
R1(config-subif)#ip address 10.10.10.1 255.255.255.0
R1(config-subif)#exit
Similarly, let us create a subinterface for VLAN 20
R1(config)#interface gigabitEthernet 0/1.20
R1(config-subif)#ip address 10.10.20.1 255.255.255.0
Configuring IP routing on a LAN subinterface is only allowed if that
subinterface is already configured as part of an IEEE 802.10, IEEE 802.1Q,
or ISL vLAN.
If we assign an IP address before the encapsulation, this error message will pop up.
R1(config-subif)# encapsulation dot1Q 20
R1(config-subif)#ip address 10.10.20.1 255.255.255.0
R1>show ip route
Codes: L – local, C – connected, S – static, R – RIP, M – mobile, B – BGP
D – EIGRP, EX – EIGRP external, O – OSPF, IA – OSPF inter area
N1 – OSPF NSSA external type 1, N2 – OSPF NSSA external type 2
E1 – OSPF external type 1, E2 – OSPF external type 2, E – EGP
i – IS-IS, L1 – IS-IS level-1, L2 – IS-IS level-2, ia – IS-IS inter area
* – candidate default, U – per-user static route, o – ODR
P – periodic downloaded static route
The Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 4 subnets, 2 masks
C 10.10.10.0/24 is directly connected, GigabitEthernet0/1.10
L 10.10.10.1/32 is directly connected, GigabitEthernet0/1.10
C 10.10.20.0/24 is directly connected, GigabitEthernet0/1.20
L 10.10.20.1/32 is directly connected, GigabitEthernet0/1.20
Let us verify and try to ping a PC in VLAN 20 from a PC configured with VLAN 10.
C:\>ping 10.10.20.10
Pinging 10.10.20.10 with 32 bytes of data:
Reply from 10.10.20.10: bytes=32 time<1ms TTL=127
Reply from 10.10.20.10: bytes=32 time<1ms TTL=127
Reply from 10.10.20.10: bytes=32 time<1ms TTL=127
Reply from 10.10.20.10: bytes=32 time=11ms TTL=127
Ping statistics for 10.10.20.10:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 0ms, Maximum = 11ms, Average = 2ms
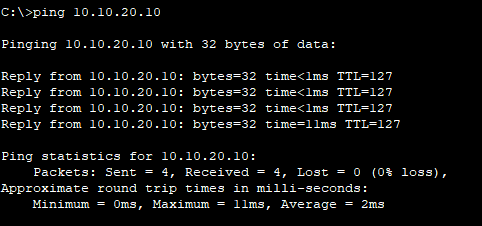
See two different VLANs are now allowed to communicate with each other.