What is an IP ADDRESS?
The IP address, known as Internet Protocol Address, is the address of your devices on the internet.
Suppose you want to call and invite your friends for a weekend party but don’t have their phone numbers. You decide to visit and invite them personally, but remember that you do not have their addresses either. The weekend is RUINED.
So, we need a phone number to make a call and an address to visit their place.
Similarly, all the devices with internet connectivity in a network need an address to communicate with each other. The address should be unique to reach the correct network devices.
The server of Amazon needs a different IP Address than that of Flipkart so that if you want to reach Amazon, you don’t get redirected to Flipkart.
Also, your computer devices need to have a unique IP Address so that when Amazon responds to your request, it does not reach any other devices.
So, an IP Address is a logical address assigned to every device in a network. It allows a host on one network to interact with the host on a different network.
What are bits and bytes?
Bit: Bit is the smallest unit of storage. It is either 1 or 0
Bytes: A collection of 8 bits is known as Bytes
What are the types of IP Addresses?
IP Addresses are of two types.
IPv4:
IPv4 is a set of 4 dotted decimal numbers, each number is known as an octet or bytes, and each octet is divided by a dot. IP Addresses can be depicted in the following three ways:
- Dotted Decimal – 172.16.30.55
- Binary – 10101100.00010000.00011110.00110111
- Hexadecimal – AC101E37
Look at the binary notation of the IPv4 IP Address. IPv4 is made up of 32 binary bits, which are divided into four parts known as octets (because of 8 bits). Each decimal ranges from 0 to 255 or 00000000 to 11111111 in Binary notation. IPv4 has around 4.3 billion IP Addresses which signifies that around 4.3 billion network devices can connect simultaneously (2^32 = 4294967296)
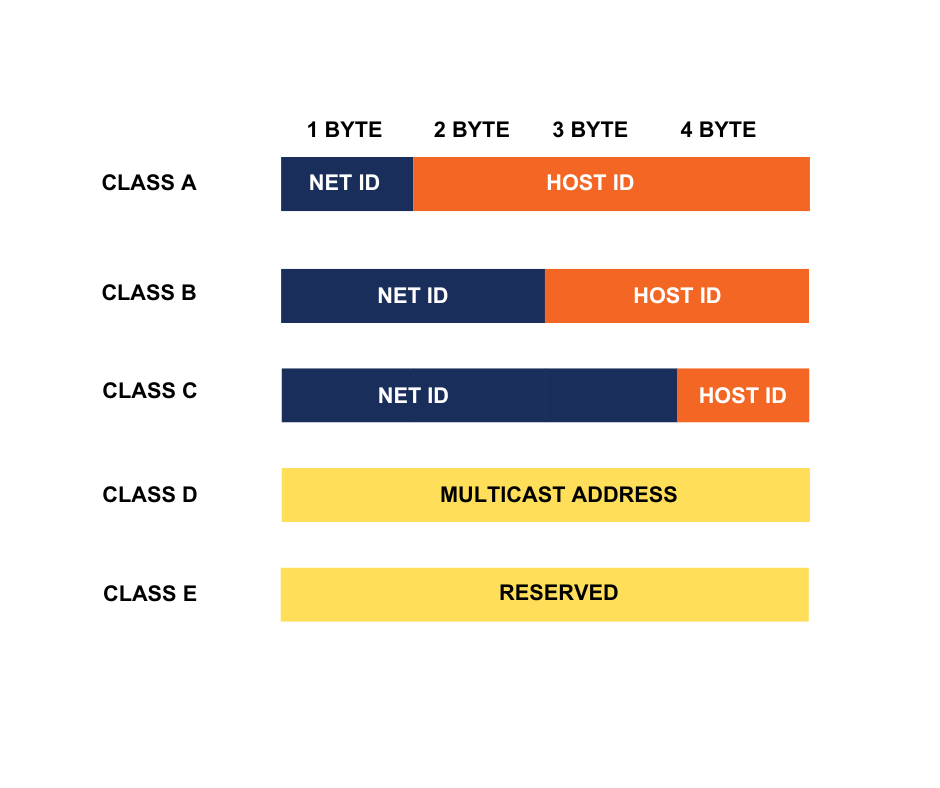
Classes of IPv4
IPv4 is divided into five classes-
Class A
- Class A ranges from 0-127
- It is used for default routing (0.0.0.0/0) and LAN card testing (127.0.0.0 to 127.255.255.255)
Class B
- Class B ranges from 128-191
- APIPA (Automatic Private IP Addressing) in DHCP uses this class range (169.254.0.1 to 169.254.255.254)
Class C
- Class C ranges from 192-223
- There is no reserved IP in this Class
Class D
- Class D ranges from 224-239.
- This class is reserved and not assigned to devices.
- This class is used for Multicasting purposes.
Class E
- Class E ranges from 240-255
- This class is reserved for research and development purposes.
Class | Range | Subnet Mask | Default CIDR |
Class A | 0-127 | 255.0.0.0 | /8 |
Class B | 128-191 | 255.255.0.0 | /16 |
Class C | 192-223 | 255.255.255.0 | /24 |
Class D | 224-239 | N/A | – |
Class E | 240-255 | N/A | – |
The first octet of Class A represents Network ID
The first 2 octets of Class B represent Network ID
The first 3 octet of Class C represents Network ID
IPv6:
Although IPv4 has around 4.3 billion addresses which seems to be a lot, network devices already crossed the set mark. Hence, IP Addresses were scarce. IPv6 comes to the rescue. IPv6 is a 128-bit address represented by 8 Hexadecimal numbers separated by colons (:).
For example – 2620:cc:8000:1c82:544c:cc2e:f2fa:5a9c.
Ipv6 has a total of 2^128 addresses which is enough as of now.
To understand in detail about IP address and its types, do watch this highly informative video by our super mentor Atul Sir wherein he has dissected every possible information about IP address:
What is the difference between IPv4 and IPv6?
- IPv4 is a 32-bit protocol, while IPv6 is a 128-bit protocol.
- In the case of IPv4 bits are separated by a dot(.) but in the case of IPv6, binary bits are separated by a colon (:).
- IPv6 is alphanumeric but IPv4 is numeric.
- Checksum fields are supported by IPv4, but not in the case of IPv6
- Variable Length Subnet Mask is supported by IPv4 but not by IPv6
Note: Read out this blog to learn difference between IPV4 and IPV6 in Detail.
What is the classification of IP Address?
Private IP Address:
Each device connected to Local Area Network is assigned Private IP Address. It is a local address and cannot be used to go to the internet.
It is assigned by your local gateway router and is visible only in the internal network. Devices on the same network are assigned unique Private IP Addresses so that they can communicate with each other. Two different LAN networks can have the same Private IP address as these IP Addresses are not routable to the internet, hence no issue will arise.
For example – Your computer and your friend’s computer sitting at different locations can have the same Private IP Address.
Public IP Address:
Public IP Addresses are assigned by your Internet Service Provider (ISP) to your router. These addresses are routable to the internet, and hence these help devices with the private address to route to the internet (using a method known as NAT).
Class | Private IP | Public IP |
Class A |
10.0.0.0 – 10.255.255.255 |
1.0.0.0 – 9.255.255.255
11.0.0.0- 126.255.255.255
|
Class B |
172.16.0.0 – 172.31.255.255 |
128.0.0.0 – 172.15.255.255
172.32.0.0 – 191.255.255.255
|
Class C |
192.168.0.0 – 192.168.255.255 |
192.0.0.0 – 192.167.255.255
192.169.0.0 – 223.255.255.255
|
Dynamic IP Address:
As the name suggests, Dynamic IP Address keeps on changing. Every time you connect your device, a new dynamic IP Address is assigned. It is allocated by your Internet Service Provider. ISP buys a large pool of IP Addresses and assigns them to their customers.
Static IP Address:
In contrast to Dynamic IP Addresses, Static IP Addresses do not change. Most internet users do not require Static IP Address. They are used by companies like Google, YouTube, Facebook, etc which means they are used by DNS Server.
- For example – The IP Address of Google is 8.8.8.8 which remains intact and does not change.
8.8.8.8 is registered as Googe.com on the DNS server. If the IP Address of Google is changing (It has used a Dynamic IP Address and not a Static IP Address), then every time user has to search for the latest IP Address of Google.com. Hence for such cases, Static IP Address is used.
Before you move further, elevate your IP knowledge base with the video below on IP Addressing and Subnetting:
Website IP Address:
These IP Addresses are used by small businesses/blog website owners who don’t have their servers and rely on hosting companies to host their websites on their behalf.
There are two types of Website Addresses-
- Shared: WordPress is an example of a shared hosting IP Address. In this case, more than one website uses the same IP Address. Most small companies use Shared IP Addresses to reduce their cost. It can be used if traffic on your website is not huge.
- Dedicated: It is the IP Address that is used by a single company. A dedicated Website IP Address is used when traffic on a particular website is usually high. It is much more secure than Shared Website IP Address.