Are you keen to learn more about Google Cloud Platform’s Dataflow service and how it might benefit your organization? So let us discuss what is Dataflow in GCP.
GCP Dataflow is a revolutionary tool that helps streamline data processing, providing businesses with the capability for swiftly managing vast amounts of datasets on the cloud. Through this efficient platform, organizations can take advantage of powerful technologies such as BigQuery and Data Pipeline from Google to make huge workloads achievable easily.
This blog post will delve into what exactly GCP Dataflow does and demonstrate how it works; so read on if you want to get maximum value out of your data management endeavors!
Overview of Google Cloud Platform (GCP)
Lately, the Google Cloud Platform (GCP) has been gaining a lot of attention and it is not hard to see why. It is an incredibly powerful cloud computing platform that provides businesses all over the world with various services – from web hosting to app development or even data storage solutions. With GCP you can make the move towards cloud technology convenient and smooth sailing!
And if you are looking for something more specific, then consider checking out their offering of Google Dataflow – which is a fully managed serverless data processing service; that allows users to create pipelines that will transform and process information in real-time as well as batch modes. Quite innovative stuff indeed!
Dataflow provides great scalability and efficiency, with no need for manual optimization or infrastructure management – everything is taken care of. This platform also allows developers to quickly create pipelines that can be adjusted according to the requirements of their application. As well as this, Dataflow provides SQL support which gives coders access to advanced analytics features using plain old SQL commands they know and love. On top of all that, applications built on Dataflow have direct access to TensorFlow integration – allowing developers to implement predictive models into their programs easier than ever before! Who could ask for more?
Google’s dedication to safeguarding data from start to finish is certainly commendable – all info handled by Dataflow is encrypted, both during transit and when stored, as standard with no additional configuration needed on the user side. Plus, extra layers of protection such as encryption keys can be arranged if further defense against unauthorized entry is required.
Consequently, organizations don’t have to fork out large initial amounts for them to make use of this service whilst still having the opportunity to quickly ramp up their capacity whenever necessary due to its pay-as-you-go technique. All things considered, Google Cloud Platform’s Dataflow solution provides a profoundly adaptable way for developers and businesses alike to process colossal volumes of information securely and efficiently – which makes it an ideal pick for anyone who needs a dependable enterprise platform designed for processing data! Wouldn’t you agree?
Key terms Definitions: What is Dataflow in GCP, BigQuery
Considering Google Cloud Platform (GCP), two of the fundamental terms to learn about are “Dataflow” and “BigQuery”.
Dataflow is a helpful service from GCP that helps developers, data engineers as well and data scientists in handling big datasets efficiently. It does this by taking raw information into its system, reorganizing it so that useful insights can be derived out of it eventually leading up to outputting these results back on BigQuery.
Now coming towards BigQuery – it is an incredibly reliable cloud-based database open for use without requiring any servers and able to maintain huge amounts of structured info at once with no issues if you wish to scale the amount up or down depending upon requirements.
Many people find Dataflow a more straightforward approach when it comes to dealing with large amounts of data compared to traditional methods like manual coding in SQL. What makes this even better is its user-friendly interface and state-of-the-art features, such as streaming processing, which allow users to construct robust pipelines for their big data needs without worrying about compromising on performance or precision. Plus, thanks to BigQuery integration you can store your converted datasets securely – no need to concern yourself with database maintenance!
If you are after quick access to big datasets without investing too much effort in the setup process, then Dataflow is a great tool for you. Plus, it has got applications beyond analytics – like machine learning and AI where developers need access to vast amounts of training data, which can be processed quickly using its robust APIs. The icing on the cake?
Google has made its managed services so that anyone – regardless of technical knowledge or resources at hand – can use them easily! All this makes GCP’s Dataflow an ideal choice if you are looking to get into leveraging big data within your organization but don’t want all those hefty costs associated with setting up traditional systems from scratch.
Understanding the Basics of Dataflow in GCP
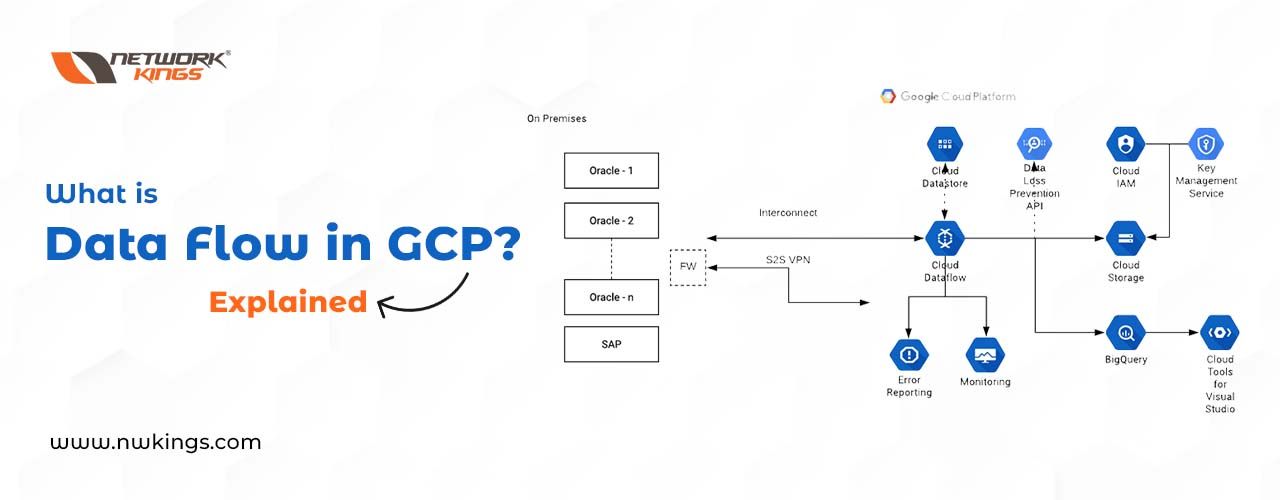
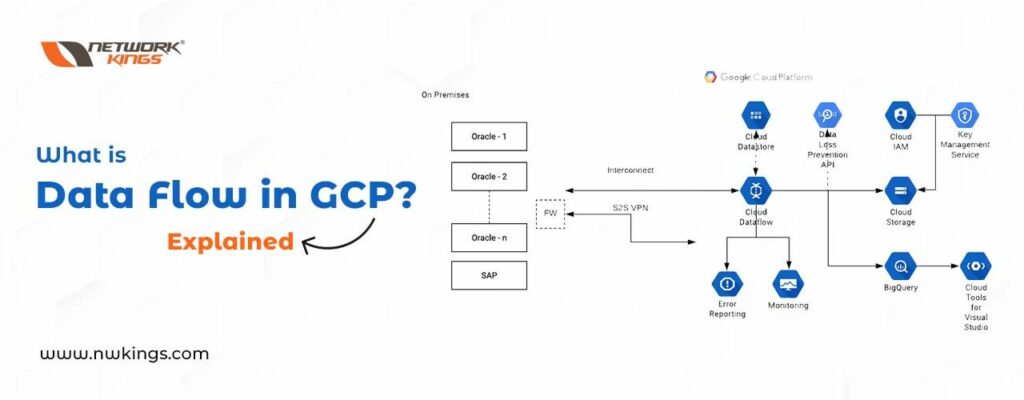
Getting to grips with Google Cloud Platform’s (GCP) Dataflow SDK is a great way for businesses to simplify data processing, both in batch and streaming forms. It provides a unified programming model that makes it easier than ever before to extract transform and load huge amounts of data. Plus, not only can companies build and manage their pipelines but also analyze the data too – giving them access to real-time insights all thanks to its three major components: Data Sources, Dataflows, and Outputs.
Data Sources are the places where data lives – like files or databases. This is what you feed into your pipelines, so it is important to make sure that this information is accurate and up-to-date.
Then there is Dataflow which contains instructions on how to handle and process all of this incoming data from these sources.
Lastly, Outputs represent where you are going to send the processed info afterward; whether it be a file or database again for example.
It feels quite complex but if we break each part down one by one then surely things will become much clearer!
Dataflow from GCP offers an array of capabilities, such as user-defined functions (UDFs), the capacity for temporal calculations like sliding and tumbling windows; auto resizing with adjustable scaling rules; distributed storage of interim outcomes; dynamic error correction; robustness against failed jobs performance and help for Kubernetes clusters – all these features make it effortless to build custom pipelines that cater exactly to your needs.
The significant benefit offered by using DataFlow SDK is scalability: this program can scale itself depending on incoming traffic without any manual input needed. This serves well when you have applications that require different speeds at separated times – marketing campaigns or machine learning workloads say – guaranteeing optimized utilization across the lifespan of those activities.
Plus, Dataprep service simplifies data prep work intended towards analytics or ML training via providing a dependable GUI plus advanced options accessible through API requests so there is no need to compose intricate SQL questions or code afresh each time prepping datasets is necessary.
The Concept of Google Cloud Dataflow
Google Cloud Platform (GCP) has a truly handy tool to process data – it is called Dataflow. This is a managed service that simplifies the process of setting up and maintaining your own highly efficient data pipeline. It can help organizations streamline their workflows and drastically cut down on time spent configuring or managing pipelines for their data. In the GCP cloud environment, you will be able to set up streamlined streaming batch processing with ease! Wow!
Put in simple terms, Dataflow allows you to use either your code or pre-made services to carry out calculations on data sets such as streaming analytics, machine learning, ETL pipelines, and more. This approach can be a lifesaver for engineering teams when it comes down to sparing them time and resources that would otherwise have been spent on constructing the infrastructure from scratch. It is also worth noting that with multiple programming languages like Python and Java available Dataflow gives developers scope of how exactly they should design their tasks.
In case folks are searching for something simpler than piecing everything together manually by coding; Google Cloud Platform (GCP) offers an AI automation feature known as Cloud Dataflow Autoscaling (CDA). CDA can help cut operational costs by automatically increasing or decreasing depending on the usage patterns, maximizing performance whilst minimizing human interference. That is why Dataflow is such an invaluable asset for any company dealing with a lot of data; it puts together all the necessary parts into one service that can be used straight away across various applications.
Plus, controlling your dataflows in GCP tends to be much easier than managing them at home due to its user-friendly interface and scalable options – making it great for small businesses as well as large ones! And then there is also its ability to link up with other GCP services which allows you to construct fully integrated solutions without needing to recreate each component every time you want to launch something different or update existing projects.
Benefits of Using GCP Dataflow in Data Processing
Google Cloud Platform’s (GCP) Dataflow is getting increasingly popular in the data processing world. The most notable advantage of using GCP Dataflow for data handling lies in its capability to simply process intricate and large-scale datasets not requiring manual coding – this not only makes it time-saving but also helps cut down on the cost of sustaining expensive programming teams. On top of that, due to running under Google’s far-reaching cloud infrastructure, you can handle your datasets from any location with remarkable velocity and dependability. What a relief!
One of the brilliant advantages of using GCP Dataflow is its simple platform for designing custom pipelines and ETL jobs with minimal fuss. You have a wealth of effective tools like transformations, aggregations, and machine-learning operations at your disposal – allowing you to make the most out of all that data! What’s more, GCP has an integrated scheduler so it can run certain tasks or full pipelines on a set schedule; making things simpler if there are regular actions such as database backups or log analysis that need doing. Lastly, when dealing with sensitive data sets rest assured knowing that Dataflow in GCP upholds secure security protocols too.
With its inbuilt integration with Google Active Directory and Identity Access Management services, you can make sure that only authorized people get access to sensitive info. To add further security Dataflow employs encryption algorithms just like the Advanced Encryption Standard (AES) 256-bit encryption protocol – so your confidential data always stays safe!
All things considered, GCP Dataflow provides a great way of managing mammoth amounts of information swiftly, safely, and proficiently. It brings lots of features that simplify workflows with maximum privacy protection all the time. So why not give it a go now?
Role of GCP Dataflow in Data Pipelining
Google Cloud Platform’s Dataflow is an incredibly handy tool for managing big volumes of data. It has been developed on Apache Beam, a freely available framework that presents a unified programming model to cope with both batch and streaming information processing needs.
GCP Dataflow allows coders to design flexible pipelines that can get the info from diverse sources, process it accurately, and then transfer it optimally to its destination point. Its scalability features plus fault-tolerance characteristics make sure your pipeline remains persistent even when individual elements are not operating correctly – this ensures GCP Dataflow keeps your operation running dependably at all times!
GCP Dataflow has an array of options that make it a doddle to define your data pipeline and deploy it multiple times with various schedules depending on the API conditions. There is manual scheduling, Automatic Trigger Scheduling, or Periodic Scheduling – you have plenty of choices! With backpressure control in GCP DataFlow as well, managing higher throughput jobs is made easier while still making sure there are resources optimally utilized.
Furthermore, techniques such as autoscaling and parallel execution allow for maximum efficiency when running distributed workflows due to breaking down large tasks into smaller ones which can then be simultaneously run using shared resources across clusters. What’s more – no extra software development or customizations are needed since GCP provides native support for popular open-source technologies like Apache Spark & Hadoop MapReduce. How convenient!
Integrating GCP Dataflow with Google BigQuery
When dealing with large amounts of data in the cloud, it is essential to have an efficient and reliable way of processing it. Enter Google Cloud Platform’s Dataflow – a service that lets you create powerful pipelines for extracting, transforming, and loading (ETL) data from any source quickly and accurately. Using these advanced pipelines alongside GCP BigQuery provides exceptional value when looking at end-to-end data processing operations – allowing users to save time while gaining insights faster than ever before!
But how exactly does this combination work? Well, establishing simple communications between DataFlow & BigQuery means your whole operation can be managed as one single entity; making things easier to monitor or understand while also providing more effective results due to leveraging both services’ strengths concurrently. It is quite remarkable how far we have come since manual database management processes which often require lots of hard labor – not only do these automated solutions save time but they are much less prone to human errors too!
Having GCP Dataflow integrated with BigQuery gives you a straightforward approach to ingesting, cleansing, and processing large volumes of data in real-time. With the streaming capacities of Dataflow, input from any source can be quickly transferred into transformations like filtering or sorting – without having intermediate collections stored first. Rather than storing the results here, these transforms can then be straight away fed into BigQuery for additional analysis or storage purposes; providing speedy insights that are ready as soon as they are needed! How cool is that?
This combination of Google Cloud Platform Dataflow and BigQuery allows you to construct incredibly responsive architectures that keep up with the ever-changing business needs. Plus, it provides comprehensive insights into customer behavior or market trends in a fraction of the time compared to traditional ETL processes.
What’s more, integrating GCP Dataflow with BigQuery offers scalability too – depending on your specific use case, you can easily scale up or down both components independently without impacting performance or reliability downstream. Furthermore, thanks largely to Bigquery’s slick query optimizer taking care of most optimization tasks for us; the workload across all other components is evenly distributed ensuring optimal resource utilization at all times which stops any component from becoming overwhelmed by an excessive amount of data being sent through it!
Stepwise Guide on Running Dataflow Jobs in GCP
Regarding cloud computing, GCP is a leader. In addition, when it comes to data processing Google’s Dataflow provides the method of choice. It is a managed service from GCP which makes it easier for developers and businesses to create dependable data pipelines for streaming analytics machine learning and batch jobs with minimum work expended. But how do you launch a Dataflow job on the Cloud Platform?
This blog will delve into setting up as well as running an efficient yet quick Dataflow job in GCP step by step so all your required processes can be done effectively!
Taking the first step into running a DataFlow job on GCP requires creating a template. This means customizing your code so you can use it for various inputs, without having to replicate each time – making life easier! You have two options when writing templates: Python or Apache Beam (which is an open-source framework that helps with parallel data processing pipelines). Having written your template, Cloud Deployment Manager should be used to bring it all together and deploy accordingly.
Once the deployment is finished, it’s time to get those triggers up and running that will start your pipeline automatically with certain input parameters you already outlined in the template. That can either be determined by timing – say for instance once every hour – or rely on external factors like user behavior differences or stock market changes. It will make all the difference when these are successfully set up!
If you are keeping an eye on stock prices, then as soon as there is a change in those stocks your trigger will fire automatically and run the pipeline with relevant parameters passed via API calls or webhooks from third-party services such as Slack or Twitter. Once that is all set up, the only thing left to do is submit the job itself! The simplest way of doing this is through Google Cloud Platform Console but if required it can also be done using APIs rather than relying on that interface.
Right, so what exactly is Dataflow? In short, it is an abstraction layer over distributed systems that allows us to run complex computations on large datasets without having to manage complicated infrastructure like clusters and combat operational issues such as failed jobs because of node failures. It offers scalability too – you can scale out horizontally by adding more nodes or expand vertically if need be, all while making sure fault-tolerance stays in place so no computation gets flummoxed due to system errors.
But how does this help with GCP? Well, these APIs allow you to monitor activity within your pipelines in real-time which means any hitches during execution are identified quickly and amended before significant damage is done: a major bonus for both time frames and money spent since the debugging process becomes simpler while ensuring there is next to no charge concerning wasted compute resources! That wraps up our brief insight into running a Dataflow job via GCP – Hopefully, now you have better awareness about what goes down behind the scenes when large-scale work needs doing!
Real-World Applications of GCP Dataflow
Dataflow in GCP is a cloud-native, absolutely managed data processing service that assists users in deploying and performing both batch and streaming data pipelines. Its scalability, as well as flexible platform capabilities, make it suitable for numerous real-world applications. A usual example of this could be the research of IoT data where by taking benefit from Dataflow’s effective analytics capacities, customers can process enormous quantities of big information from IoT gadgets generating valuable insights.
Another use case for GCP Dataflow would be examining user behaviour on digital platforms such as websites or mobile apps – what kind of content do they prefer; how much time are people spending online etc.? This way companies will acquire relevant feedback about their services and products helping them stay competitive in the market!
With Dataflow, developers can concoct custom pipelines to observe user engagement trends in real-time which they then use to inform decisions for product design or marketing campaigns. Analytic streaming in real-time also gives companies the power to detect fraudulent activities quickly and take appropriate action before it is too late.
GCP Dataflow is a useful tool that helps businesses identify customer segmentation opportunities by analyzing data such as demographic details or purchase history. With machine learning algorithms users can classify customers into distinct groups based on their behaviours and preferences thereby providing marketers with more targeted audiences for their campaigns.
That is not all; GCP Dataflow has an application in healthcare settings too! By merging patient medical records with environmental readings from sensors or devices like wearables doctors can understand how external factors may be affecting a patient’s health or recuperation process better – this helps medicare providers offer treatments tailored specifically for individual patients rather than generally accepted guidelines only. How incredible would it be if doctors had access to such information?
Understanding Costs and Pricing in GCP Dataflow
Understanding the costs and pricing of data processing tasks with GCP Dataflow can be tricky. It is essential to comprehend all elements that contribute to your bill when applying Cloud DataFlow – this way you can make sure you are getting good value for what you spend. So, let us start by exploring what exactly Google Cloud Platform (GCP) DataFlow is. Essentially it is a managed service for large-scale cloud computing. With one program model, both batch and streaming applications are available on the Google Cloud Platform – easy peasy!
Right, now that we have a basic understanding of what GCP Dataflow is all about, let us talk costs. It affects your pocket in two ways: Compute charges and Storage charges. The compute fees are based on the length of time you are running your job or jobs over an instance (or instances). Pretty simple so far – but how does this tie into cost savings?
Well, when it comes to processing data at scale with Apache Beam through GCP DataFlow, as long as you keep your pipelines short-lived then there will be significant cost reductions compared to other services such as AWS or Azure, etc; which may take longer due to their pricing structure model being ‘per hour’. So if you want lower bills for larger workloads over shorter periods then Google Cloud Platform might just be the one for you!
When it comes to resources consumed by jobs, CPUs, GPUs, and storage space used for storing the input or outputs of each job all come into play. How much your storage charges will be is determined by how many data sets you have stored on either Google Cloud Storage or BigQuery tables that are necessary for every job run. Therefore, when scaling up or down your workload over time you should take special consideration as this can make a huge difference in terms of what ends up being paid overall if care isn’t taken! Have you thought about how pricing might work across different scales? It is worth taking some time to consider before making any changes.
When it comes to scaling up a pipeline quickly, there will be an inevitable increase in computing costs. This is because you have to spin up more instances and pay for additional storage space if data needs to be written out quickly from those new instances. On the other hand, when scaling down workloads the opposite happens – computing costs go down yet still paying for any unused storage which isn’t being used due to dropped pipelines any longer writing output files thus reducing resource utilization significantly compared to before. One might easily overlook this expense unless actively kept track of particularly while dealing with large datasets! Is it always necessary to pay for so much extra storage?
Wrapping Up!
In conclusion, GCP Dataflow is hugely beneficial for businesses looking to effectively manage their data within the Google Cloud platform. It is not only a great tool for creating efficient and scalable data pipelines – it can also be used in combination with BigQuery to handle large volumes of information. So if you want an easy-to-use solution that will serve your business well into the future, then GCP Dataflow may just be what you need!
Are you keen to boost your knowledge and get a grip on the up-to-date cloud architecture? Then why not sign up for our Cloud Architect Master Program? We have designed this program so that it gives you everything required to build reliable, secure, and flexible cloud solutions.
You will be able to learn from industry authorities in both concepts and practical abilities which will let you further enhance your qualifications for applying for prestigious jobs in the IT sector. Our program provides access to an extensive course library with modules on topics including Cloud Architecture Designing and Optimisation, Security of Cloud Platforms, Infrastructure as Code plus much more!
You can also benefit from hands-on training experiences meaning that you are able to practice all those fresh abilities inside a simulated atmosphere working with real-life scenarios – what’s stopping you?! Enroll now and gain access to tools plus resources essential to becoming great at being a successful Cloud Architect!
Are you on the lookout for a career boost in this ever-changing digital world? We have got just what you need! Our Cloud Architect Master Program is tailored to help develop your key skills and understanding that’ll enable planning, designing, and constructing cloud architectures. With us by your side, you would be able to work proficiently with top public cloud providers including Amazon Web Services (AWS), Microsoft Azure, as well as Google Cloud Platform.
You will also gain access to cutting-edge technology like Artificial Intelligence (AI), Machine Learning (ML), Internet of Things (IoT), Big Data Analytics plus Blockchain – all ready for learning hands-on! Become an ideal candidate employers seek now in the current market; don’t let go of this amazing program – enroll today so get ahead of others in no time at all!
Happy Learning!